在前一篇,我們認識並學會了使用Chat Template讓模型能理解誰在說話。
但模型要真正開口說話,就需要進入生成階段。
這一篇,我們要來了解模型是如何一步一步預測下一個字(token)的。
1. 根據輸入的prompt一次產生一個token。
我們先從最基本的情境開始,讓模型根據提示詞prompt,只產生一個token。
流程:prompt ⟶ tokenizer.encode ⟶ input_ids ⟶ model ⟶ output ⟶ probabilities ⟶ top_k token ⟶ tokenize.decode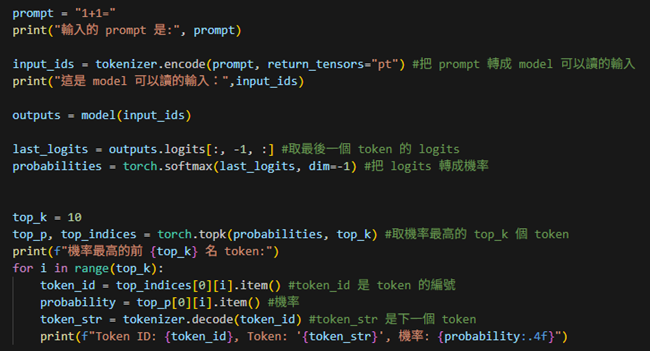
2. 根據輸入的prompt一次產生多個token。
再來我們要讓模型連續生成,模擬一段完整的句子。
每次產生一個token,就把它接回prompt裡,再繼續往下預測。
流程:prompt ⟶ tokenizer.encode ⟶ input_ids ⟶ model ⟶ output ⟶ token_str(prompt=prompt+token_str)重複length次(停止條件:生成代表結束的token或到長度上限)。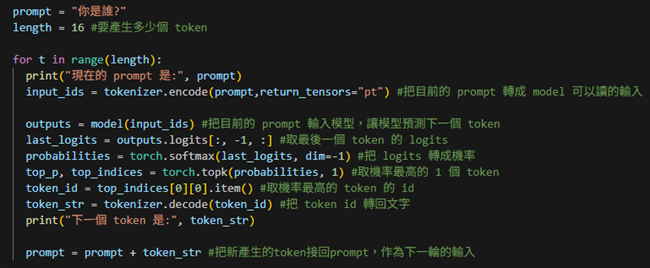
 妤
妤

 iThome鐵人賽
iThome鐵人賽